

به عنوان یک مهندس داده زمانی که میخواهید یک خط انتقال داده (data pipeline) را طراحی و پیاده سازی کنید احتمالا اولین سوالی که باید به آن پاسخ دهید این است که؛ چه معماری و ابزارهایی برای طراحی و ساخت این پایپ لاین انتخاب کنم؟ پاسخ این سوال بر اساس معیارهای مختلف مثل جنس داده، سرعت تولید داده، کاربرد نهایی و موارد دیگر می تواند متفاوت باشد. هر معماری که انتخاب می کنید (با وجود تمام تفاوت هایی که می توانند داشته باشند) باید قادر باشید به سرعت آن را توسعه (Develop) و استقرار (Deploy) دهید. همچنین باید پشتیبانی و نگهداری (maintenance) پایپ لاین ساخته شده به راحتی قابل انجام باشد. حال سوال اینجاست که، چگونه پایپلاینی بسازیم که مقیاس پذیر بوده و به راحتی قابل توسعه و نگهداری باشد؟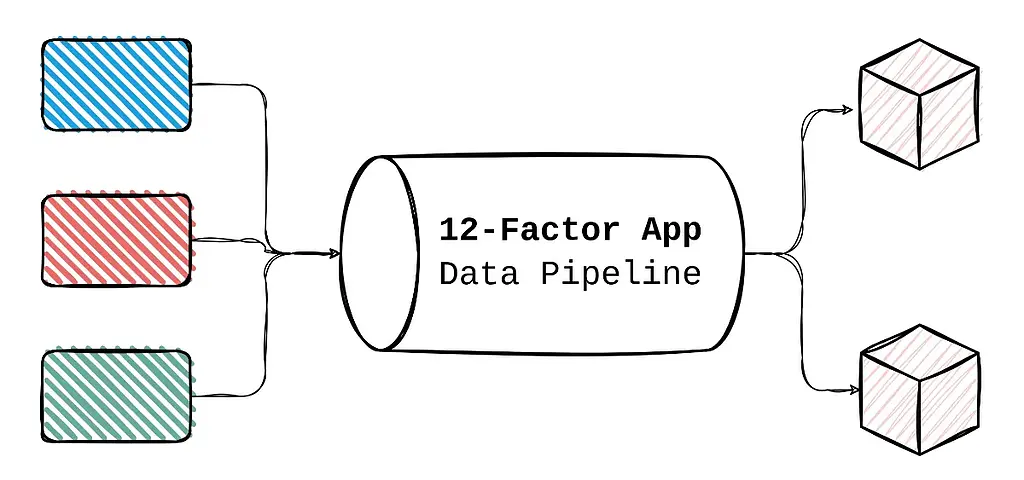
در این مقاله اصول ۱۲ گانه ای معرفی می شود که با بکارگیری آن بتوان برنامه ها و دیتاپایپ لاین هایی مقیاس پذیر ساخت. Twelve Factors App یک مجموعه از اصول راهنما برای طراحی و ساخت برنامههای مدرن و مقیاسپذیر است که در محیطهای ابری اجرا میشوند. این اصول که ابتدا توسط توسعهدهندگان Heroku تعریف شدند، به گونهای طراحی شدهاند که توسعهدهندگان بتوانند برنامههایی را ایجاد کنند که به راحتی توسعه، استقرار و پشتیبانی می شود. در این مقاله می خواهیم مزایای این متدولوژی را مورد بررسی قرار دهیم و از این اصول به عنوان چارچوبی در طراحی و ساخت پایپ لاین های داده خود استفاده کنیم.
مقدمه
متدولوژی Twelve Factor App توسط شرکت Heroku که یک بستر ارائه خدمات ابری است با هدف حل چالش های توسعه برنامه های مدرن تحت وب معرفی شد. این شرکت در سال ۲۰۰۷ تاسیس شد و جزء اولین پلتفرم هایی بود که استقرار برنامه های تحت وب (web applications) را ساده کرد. در اوایل دهه ۲۰۱۰ که استفاده رایانش ابری (Cloud Computing) و میکروسرویس ها رو به گشترش بود، نیاز به یک رویکرد و چارچوب استاندارد برای ساخت برنامه های مقیاس پذیر (scalable)، قابل نگهداری (maintainable) و قابل استقرار (deployable) آشکار شد. در سال ۲۰۱۱، Heroku مجموعه ای از ۱۲ اصل یا معیار را تحت عنوان Twelve Factor App معرفی کرد و در وبلاگ Adam Wiggins یکی از بنیانگذاران Heroku منتشر شد و به سرعت در جامعه توسعه دهندگان به رسمیت شناخته شد. با وجود اینکه این متدولوژی برای توسعه برنامه های SaaS (Software as a Service) ارائه شده است اما بهره گیری از این معیار ها می تواند برای مهندسین داده در ساخت پایپ لاین های داده ای بسیار کمک کننده باشد.
در ادامه به معرفی و بررسی هرکدام از این اصول و کاربرد آنها در ساخت خطوط انتقال داده خواهم پرداخت. برای درک بهتر مفهوم، در قالب مثال هایی، ۱۲ معیار را توضیح خواهم داد.
..........
فرض کنید یک فروشگاه اینترنتی برای تحلیل رفتار مشتریان خود نیاز دارد پایپلاینی پیاده سازی کند که داده های وب سایت و اپلیکیشن موبایل را بصورت آنی (real-time) دریافت و پردازش کند و سپس در یک انبار داده (data warehouse) ذخیره نماید. این پایپ لاین باید پایدار (stable) و مقیاس پذیر (scalable) باشد و همینطور در صورت بروز خطا کمترین تاثیر را بر کاربران و سایر بخش ها داشته باشد (fault-tolerant). برای رسیدن به این هدف اصولی را باید رعایت کنیم که در ادامه به بررسی هر کدام می پردازیم:
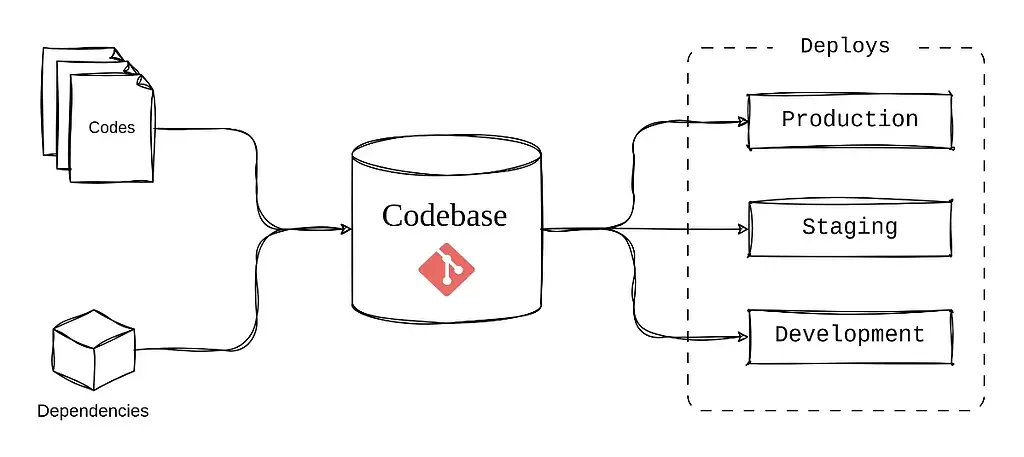
۱- پایگاه کد یا کدبیس (Codebase)
One codebase tracked in revision control, many deploys
این اصل به این موضوع اشاره دارد که تنها یک پایگاه واحد برای نگهداری کدها باید داشته باشیم اما می توانیم بارها و در محیط های مختلف مثل production، staging، development آن کد را اجرا کنیم. برنامه های ۱۲ عاملی همیشه از یک سیستم کنترل ورژن مانند گیت برای نگهداری و مدیریت کدها استفاده می کنند.
به عنوان مثال در این سناریو؛ یک کدبیس بروی Git داریم که اسکریپت های ETL، کدهای پردازش داده و تنظیمات مربوط به محیط های توسعه در آن قرار دارد. برای این مثال می توانیم سه branch در نظر بگیریم:
- برای ایجاد ویژگی های جدید و رفع ایرادات از برنچ development استفاده می کنیم.
- برای تست کد های از برنچ staging استفاده می کنیم که یک کپی یکسان (mirror) از production است.
- کدهای اصلی که دپلوی می شوند در برنچ production وجود دارند.
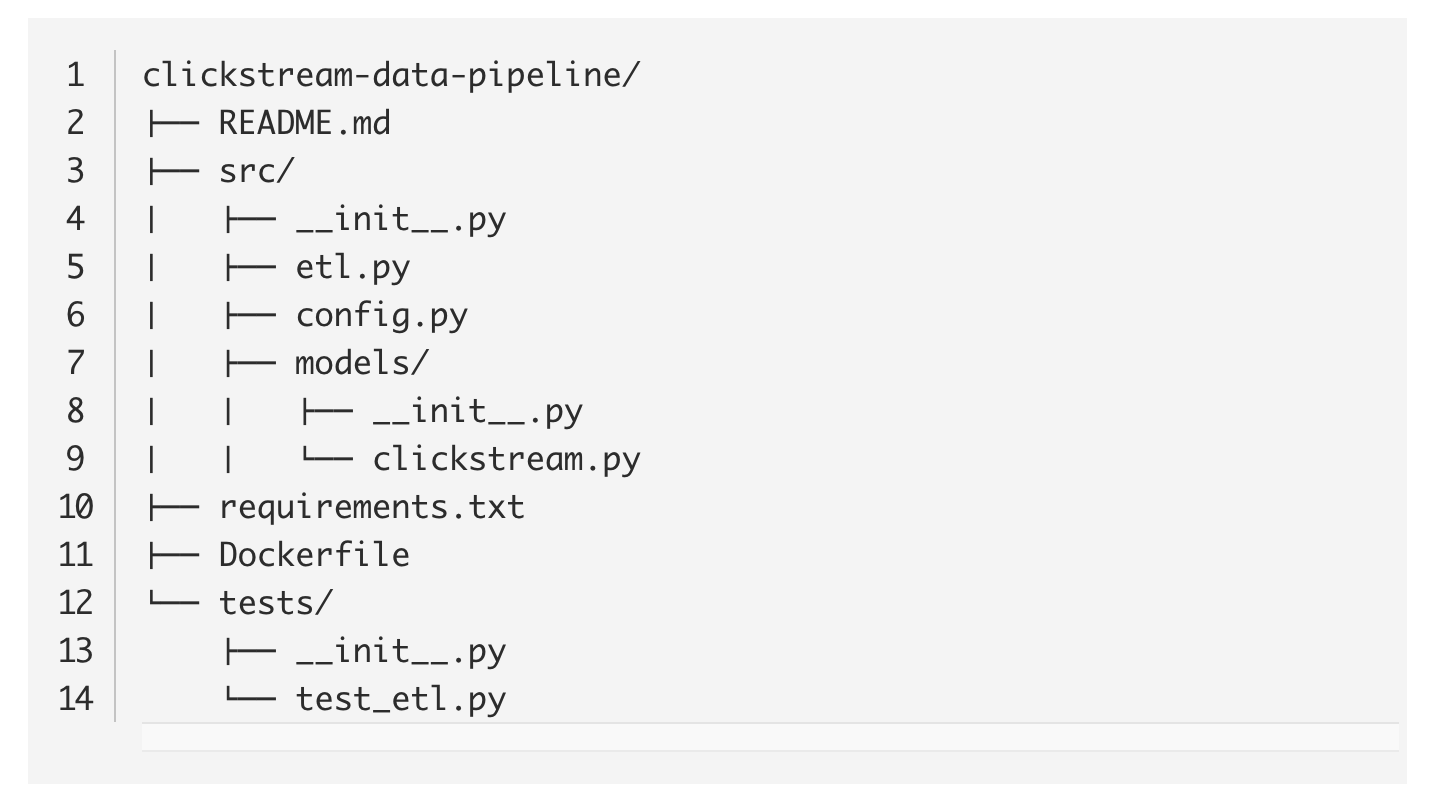
ساختار کدبیس این پروژه می تواند به صورت زیر باشد:
۲- وابستگی ها (Dependencies)
Explicitly declare and isolate dependencies
تمام وابستگی های پروژه مثل کتابخانه ها و ماژول ها را صریحاً مشخص کنید. (به عنوان مثال در فایل های requirments.txt یا pyproject.toml) و از محیط های مجازی (virtual environments) یا داکر برای ایزوله کردن این وابستگی ها استفاده کنید. این کار باعث می شود که پایپ لاین ما در همه محیط ها به درستی اجرا شود. در این پروژه کتابخانه های موردنیاز را در فایل requirments.txt مشخص کرده ایم:
pandas==2.2.2 sqlalchemy==2.0.32 psycopg2-binary==3.2.1 kafka-python==2.0.2
هممینطور از داکر برای ایزوله کردن نیازمندی ها و محیط اجرای پروژه استفاده شده است:
FROM python:3.11-slim WORKDIR /app COPY requirements.txt requirements.txt RUN pip install --no-cache-dir -r requirements.txt COPY ./src /app/src CMD ["python", "src/etl.py"]
۳- کانفیگ ها (Configs)
Store config in the environment
همیشه کانفیگ های مربوط به پروژه را در متغیر های محیطی (Environments variables) ذخیره کنید. کانفیگ هایی مثل اطلاعات اتصال به دیتابیس ها، کلیدهای API و بطور کلی هر کانفیگی که می تواند در محیط های مختلف تغییر کند. این کار باعث می شود که امنیت اطلاعات شما حفظ شود و اطلاعات حساس در کدبیس شما ذخیره نشود. همچنین می توانیم به راحتی کانفیگ ها را بدون تغییر در کدبیس عوض کنیم و استفاده از کدهای پروژه در محیطهای مختلف (develop, staging, production) آسانتر میشود.
ذخیره کانفیگ ها در متغییرهای محیطی سیستم:
KAFKA_BROKER =localhost:9092 POSTGRES_URI =postgresql://user:password@localhost/dbname
دسترسی به متغییرهای محیطی ذخیره شده:
# config.py
import os
KAFKA_BROKER = os.getenv("KAFKA_BROKER")
POSTGRES_URI = os.getenv("POSTGRES_URI")۴- سرویس های متصل (Backing-Services)
Treat backing services as attached resources
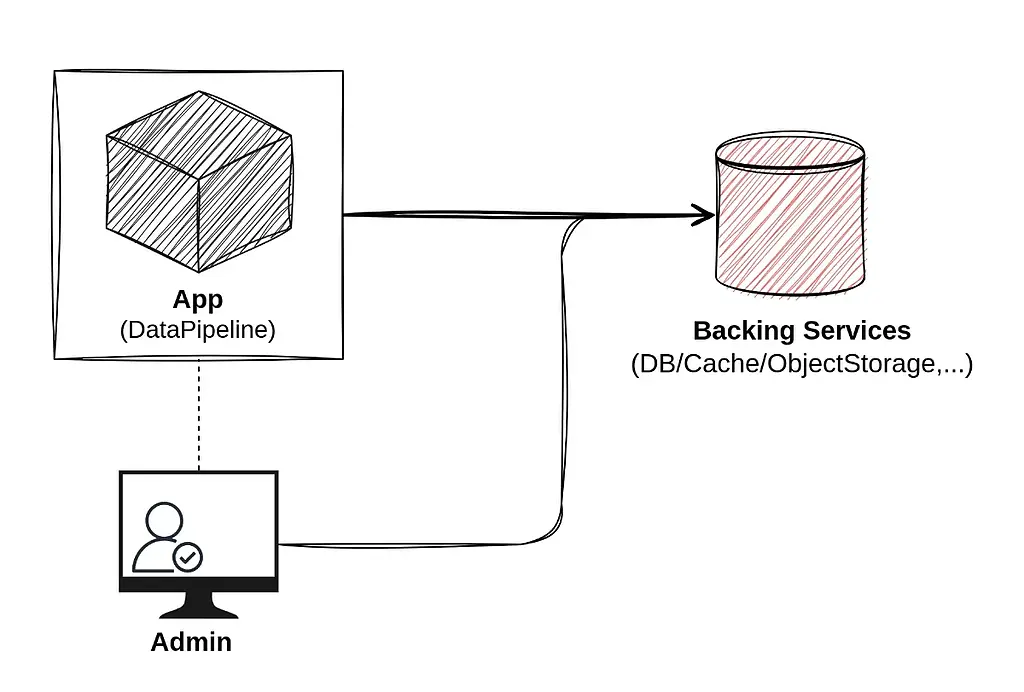
در اکثر پروژه های ما با سرویس های مختلفی مثل دیتابیس، بروکر، انواع API و... سر و کار داریم که به نوعی منابع خارجی (external resource) به حساب می آیند که برنامه ما به آنها متصل (Attach) می شود. ایده اصلی این است که بتوان درصورت نیاز سرویس هایی که از آنها استفاده می کنیم را بدون تغییر در کد عوض کنیم. کد ما باید طوری نوشته شود که بتوانید از متغیرهای محیطی به راحتی برای این کار استفاده کند. فرض کنید داده های شما در یک سرور Postgres که مدیریت آن با شما است ذخیره شده است، بعد از مدتی تصمیم میگیرید که دیتابیس خود را به یک فضای ابری منتقل کنید. شما باید بتوانید به سادگی این تغییر را انجام دهید. با جدا کردن کانفیگ ها از کد و استفاده از متغیر های محیطی به سادگی میتوانید به این هدف برسید. به شکل زیر دقت کنید:
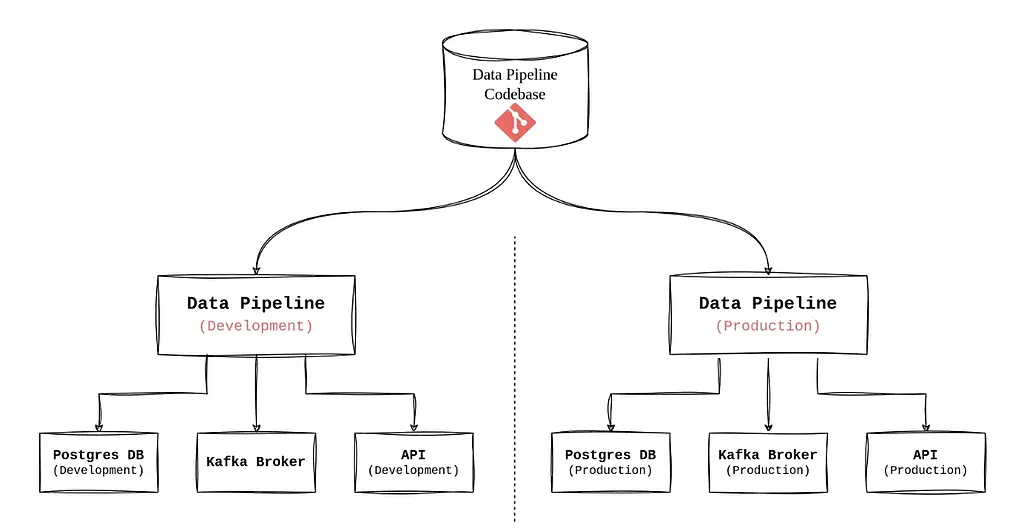
این تصویر نشان می دهد که در دو محیط مجزا یکی Development و دیگری Production از سرویس های مجزایی استفاده شده است. با اینکه کدبیس مشترکی را استفاده می کنیم اما می توانیم سرویس های خارجی مختلف با کانفیگ های متفاوت را در محیط های مجزا داشته باشیم.
# etl.py
import os
from kafka import KafkaConsumer
import pandas as pd
from sqlalchemy import create_engine
from src.config import KAFKA_BROKER, POSTGRES_URI
# Initialize Kafka consumer
consumer = KafkaConsumer('clickstream', bootstrap_servers=[KAFKA_BROKER])
# Initialize PostgreSQL connection
engine = create_engine(POSTGRES_URI)۵- ساخت، انتشار، اجرا (Build, Release, Run)
Strictly separate build and run stages
پنجمین عامل بر جداسازی مراحل استقرار (Deploy) یک برنامه تاکید دارد تا از این طریق بتوان سازگاری (consistency)، قابلیت اعتماد (reliability) و تکرار پذیری (reproducibility) را تضمین کرد. در اینجا مراحل استقرار یک برنامه به سه فاز مختلف تقسیم می شود:
- ساخت (Build): در این مرحله کدبیس برنامه به همراه وابستگی های آن به یک بسته اجرایی (Artifact) تبدیل می شود. خروجی این مرحله می تواند یک Docker image باشد.
- انتشار (Release): خروجی مرحله قبل با کانفیگ های مربوط به محیط اجرا (متغییرهای محیطی) ترکیب می شوند و یک ورژن تولید می شود. هر ورژن دارای یک شماره منحصر به فرد است. این شماره می تواند یک timestamp مثل 2024-06-06-20:32:17 یا یک عدد مثل v100 باشد.
- اجرا (Run): این مرحله جایی است که نسخه تولید شده در محیط مورد نظر راه اندازی و اجرا میشود و به درخواست های کاربر پاسخ می دهد.
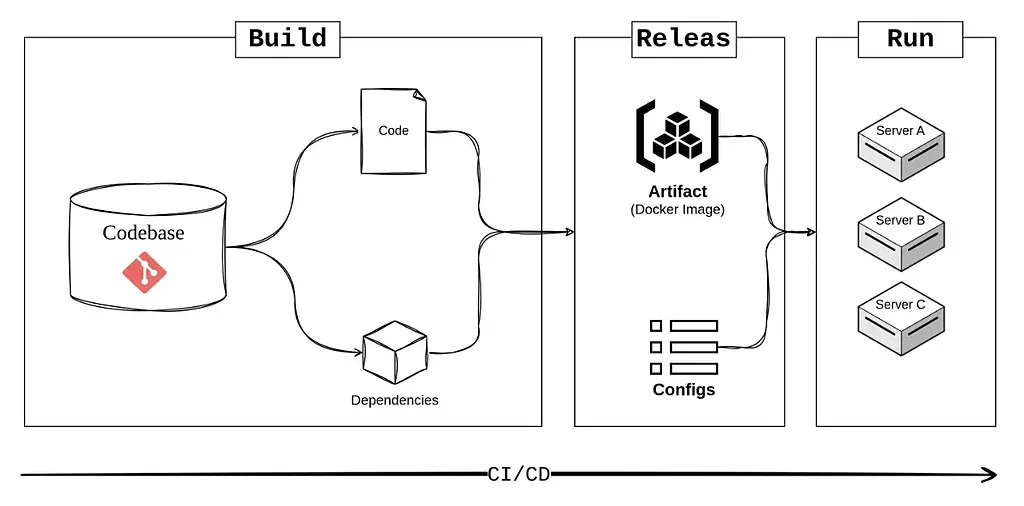
خودکارسازی انجام مراحل ساخت، انتشار و اجرا؛ با استفاده از ابزارهای CI/CD مثل GitHub Action یا GitLab در این فاز منجر به افزایش کارایی و قابلیت اعتماد پایپلاینهای داده می شود.
name: Build and Test
on:
push:
branches:
- main
pull_request:
branches:
- main
jobs:
build:
runs-on: ubuntu-latest
steps:
- name: Checkout code
uses: actions/checkout@v2
- name: Set up Python
uses: actions/setup-python@v2
with:
python-version: '3.10'
- name: Install dependencies
run: pip install -r requirements.txt
- name: Run tests
run: pytest
- name: Build Docker image
run: docker build -t ghcr.io/yourusername/etl-service:${{ github.sha }} .
- name: Push Docker image
run: docker push ghcr.io/yourusername/etl-service:${{ github.sha }}
env:
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}۶- پردازه ها (Processes):
Execute the app as one or more stateless processes
- هر برنامه ای که با استفاده از اصول Twelve-factor نوشته می شود باید بصورت Stateless و Share-nothingباشد به این معنی که اگر نیاز به ذخیره سازی داده ها داریم باید آنها را در دیتابیس یا backing service های دیگر ذخیره کنیم.
پردازه stateless به چه معناست؟ پردازه یا پراسسی stateless است که در هر بار اجرای درخواست کاربر بدون تکیه بر داده های ذخیره شده در حافظه یا دیسک محلی، درخواست را اجرا کند در اینجا اگر نیاز به ذخیره سازی وضعیت یا حالتی از درخواست کاربر را داشته باشیم باید از backing-service هایی مانند دیتابیس، کَش یا آبجکت استوریج ها استفاده کنیم.
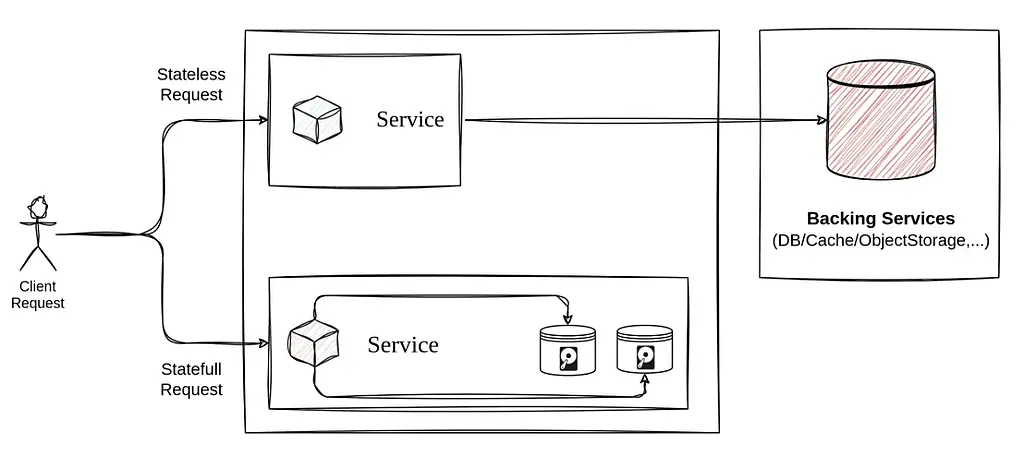
طراحی پایپلاین بصورت stateless برای ما مقیاس پذیری (scalability) را به همراه دارد.
۷- اتصال به پورت (Port Binding)
Export services via port binding
در متدولوژی ۱۲ عاملی، Port Binding اهمیت زیادی دارد، زیرا به صورت مستقیم بر نحوهٔ توزیع و استقرار برنامه در محیطهای مختلف تأثیر میگذارد.
در مدل توسعه نرم افزار بصورت کلاسیک، برنامهها معمولاً به یک وب سرویس خارجی متکی هستند (مثل Apache یا Nginx) که درخواستها را به برنامه ارسال میکند. اما در معماری ۱۲ عاملی، برنامهها خود به صورت مستقل به پورت خاصی متصل میشوند و به عنوان یک سرویس عمل میکنند. که این موضوع باعث میشود که برنامه ها بتوانند در هر محیطی (مثل تست، توسعه، یا تولید) به راحتی اجرا شوند.
در دیتاپایپلاینها برای ارتباط بین بخشهای مختلف پایپلاین و سرویسهایی که دادهها را پردازش میکنند، نیاز به اتصال و ارتباط از طریق پورتها وجود دارد و Port Binding به برنامهها و سرویسهای مختلف در پایپلاین اجازه میدهد تا در عین حال که به یکدیگر متصل هستند به صورت مستقل و مجزا کار کنند.
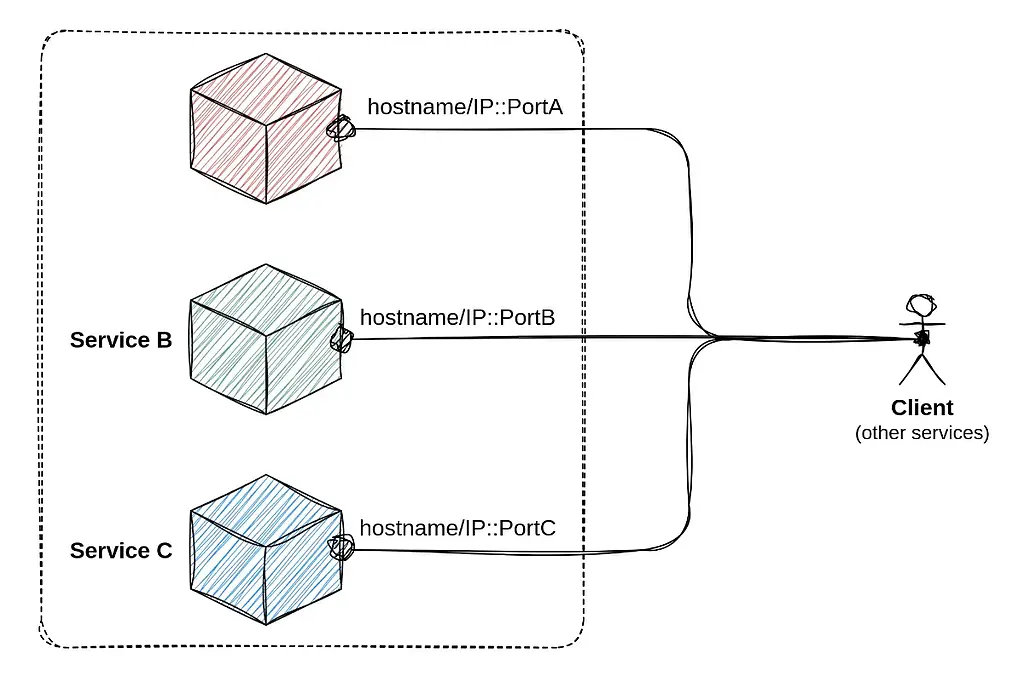
فرض کنید یک دیتاپایپلاین برای جمع آوری، پردازش و ذخیره دادههای IoT طراحی کردهاید. این پایپلاین شامل سه سرویس اصلی است:
- سرویس جمعآوری داده (Data Ingestion Service): این سرویس به پورت 8080 متصل است و دادههای حسگرها را از طریق HTTP POST دریافت میکند.
- سرویس پردازش داده (Data Processing Service): این سرویس به پورت 9090 متصل است و دادههای خام را پردازش میکند. سرویس جمعآوری داده، دادههای دریافتی را به این سرویس ارسال میکند.
- سرویس ذخیرهسازی داده (Data Storage Service): این سرویس به پورت 10000 متصل است و دادههای پردازششده را در یک پایگاه داده ذخیره میکند. سرویس پردازش داده نتایج را به این سرویس ارسال میکند.
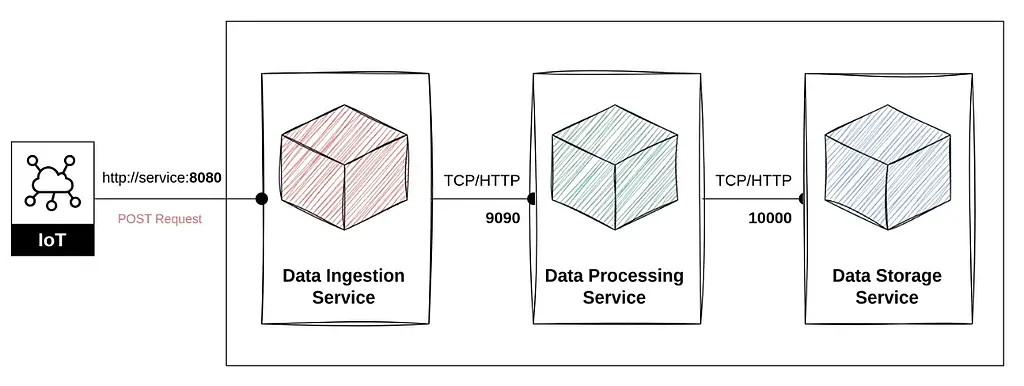
در این مثال، هر سرویس به پورت خاصی متصل است و به عنوان یک سرویس مجزا عمل میکند. این رویکرد باعث میشود که هر سرویس به صورت مستقل توسعه، تست و مستقر شود. همچنین، با این روش میتوان هر سرویس را بدون وابستگی به بقیه سرویسها Scale کرد. در کل، Port Binding باعث سادهتر شدن استقرار، مقیاسپذیری، و نگهداری برنامهها در محیطهای مختلف میشود.
from flask import Flask
app = Flask(__name__)
@app.route('/process', methods=['POST'])
def process():
# Trigger data processing
return "Data processing triggered", 200
if __name__ == '__main__':
app.run(port=9090 )۸- همروندی (Concurrency)
Scale out via the process model
اصل هشتم بر مقیاسپذیری افقی (horizontal Scale Out) از طریق اجرای چندین نمونه (instance) از پردازه یا برنامه های مستقل تمرکز دارد، به جای استفاده از یک فرآیند بزرگ و پیچیده. در ادامه، این اصل را توضیح میدهیم و یک مثال بر اساس سناریوی پایپ لاین دادهای که قبلاً تعریف کردیم، ارائه میدهیم.
- همروندی به این معناست که یک برنامه به جای استفاده از چند رشته (thread) در یک پردازش، میتواند از چندین پردازه مجزا که به طور همروند کار میکنند، استفاده کند. این فرآیندها مستقل از هم هستند و میتوانند در صورت نیاز به طور جداگانه مقیاسدهی شوند. هر فرآیند یک وظیفه خاص را بر عهده دارد، و مقیاسدهی افقی به معنای افزایش تعداد این فرآیندها برای مدیریت بار (Work Load) بیشتر است.
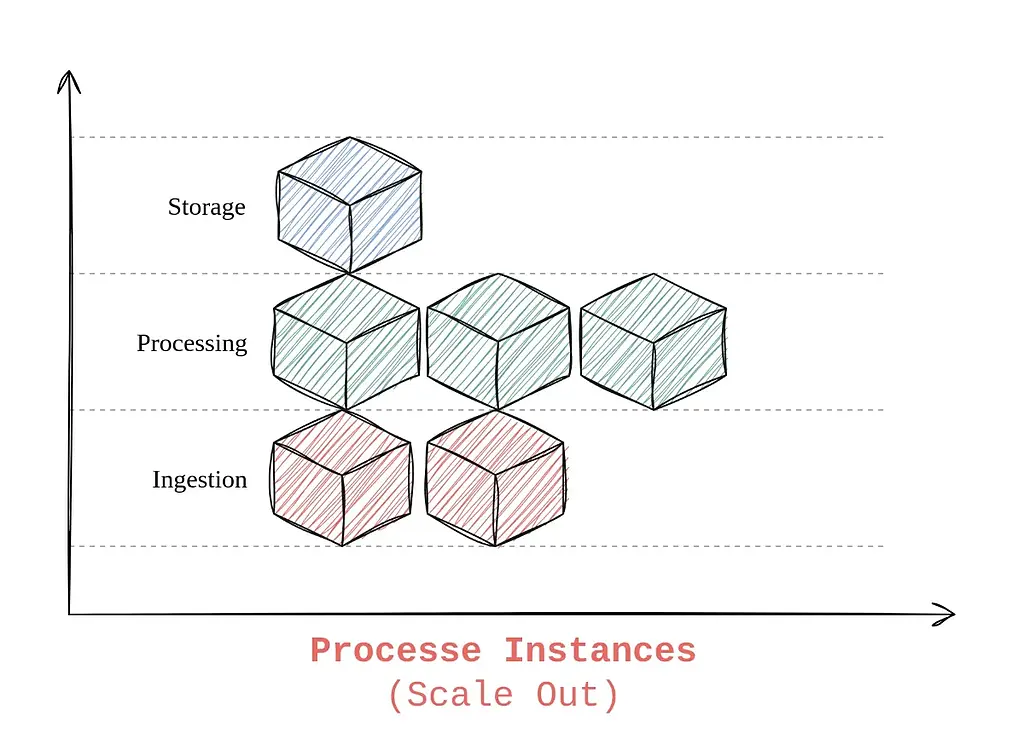
مزایای مدل پردازشی همروندی برای افزایش مقیاسپذیری افقی
- افزایش انعطافپذیری: با استفاده از چندین پردازش مجزا، میتوان به سادگی هر کدام از آنها را بهطور مستقل مقیاسدهی کرد. برای مثال، اگر بخش ورودی داده بیش از حد بار دارد، میتوان تعداد فرآیندهای مربوط به ورودی داده را افزایش داد بدون اینکه بر بخشهای دیگر خط لوله تأثیر بگذارد.
- پایداری بیشتر: اگر یکی از فرآیندها دچار خرابی شود، این خرابی تأثیری بر سایر فرآیندها ندارد. بنابراین، سیستم پایدارتر است و احتمال از دست رفتن دادهها کاهش مییابد.
- مدیریت آسانتر: فرآیندهای مجزا میتوانند به راحتی مدیریت و نظارت شوند. هر فرآیند مسئولیت مشخصی دارد و بنابراین خطاها و مشکلات راحتتر شناسایی میشوند.
برای پیادهسازی همروندی می توانیم هر کدام از سرویس ها را به عنوان یک پردازه (Process) مستقل در نظر بگیریم:
- جمعآوری داده: میتوان چندین نمونه (instance) از سرویس جمع آوری داده را به طور همزمان اجرا کرد که هر کدام دادهها را از منبع خاصی جمعآوری کنند. اگر حجم دادههای ورودی افزایش یابد، میتوان تعداد این نمونه ها را افزایش داد و به این ترتیب حجم بالای ورودی داده ها را مدیریت کرد. در مثال زیر با استفاده از داکر سه instance از یک سرویس اجرا می شود:
name: paipeline services: ingestion: image: data_ingestion_image:latest deploy: replicas: 3 # Running 3 instances for concurrency ports: - "8080:8080" environment: - DATA_SOURCE_URL=http://data-source.pipeline.com
- تبدیل داده: فرآیندهای تبدیل داده می توانند به طور موازی اجرا میشوند. هر فرآیند یک بخش از دادهها را پردازش میکند. اگر نیاز به پردازش حجم زیادی از داده باشد، میتوان تعداد پردازه های تبدیل داده را افزایش داد.
- بارگذاری داده: فرآیندهای بارگذاری داده نیز می توانند به طور همزمان اجرا شوند و هر کدام بخشی از دادههای پردازششده را در دیتابیس نهایی ذخیره میکنند.
مثال زیر نمونه ای ساده از همروندی است که با استفاده از کتابخانه multiprocessing در پایتون نوشته شده است:
import multiprocessing as mp
import time
def data_ingestion(source):
"""Simulate data ingestion from a specific source."""
print(f"Collecting data from {source}...")
time.sleep(2) # Simulate time taken to collect data
return f"Data from {source}"
def data_transformation(data):
"""Simulate data transformation."""
print(f"Transforming {data}...")
time.sleep(2) # Simulate time taken to transform data
return f"Transformed {data}"
def data_loading(transformed_data):
"""Simulate loading data into a database."""
print(f"Loading {transformed_data} into database...")
time.sleep(2) # Simulate time taken to load data
print(f"{transformed_data} loaded successfully!")
if __name__ == "__main__":
# Define data sources
sources = ['Source 1', 'Source 2', 'Source 3']
# Execute data ingestion processes concurrently
with mp.Pool(processes=len(sources)) as pool:
raw_data = pool.map(data_ingestion, sources)
# Execute data transformation processes concurrently
with mp.Pool(processes=len(raw_data)) as pool:
transformed_data = pool.map(data_transformation, raw_data)
# Execute data loading processes concurrently
with mp.Pool(processes=len(transformed_data)) as pool:
pool.map(data_loading, transformed_data)
print("Data pipeline executed successfully!")
همروندی (Concurrency) به ما این امکان را میدهد که دیتاپایپلاین های خود را به صورت انعطافپذیر، مقیاسپذیر و پایدار طراحی کنیم. با استفاده از مدل پردازشی و مقیاسپذیری افقی، میتوانیم به طور موثرتری با تغییرات در حجم داده و نیازهای پردازشی روبرو شویم و در نتیجه یک دیتاپایپلاین کارآمد داشته باشیم.
۹- اصل Disposability:
Maximize robustness with fast startup and graceful shutdown
این اصل بر قابلیت شروع سریع (Fast Startup) و خاموشی بهینه یا سالم (Graceful Shutdown) سرویسها تاکید دارد. به بیان دیگر، فرآیندهای یک اپلیکیشن باید سریعاً راهاندازی شوند و در صورت نیاز، بدون تأثیر منفی بر سیستم بهسرعت خاموش شوند. این اصل به بهبود elasticity، auto-scaling، reliability در یک سیستم کمک میکند.
- راهاندازی سریع (Fast Startup): هر فرآیند در سیستم باید بهسرعت راهاندازی شود. این به شما کمک میکند تا بتوانید به سرعت مقیاس سیستم را افزایش دهید یا در صورت خرابی، فرآیندها را به سرعت جایگزین کنید.
- خاموشی سالم (Graceful Shutdown): اگر یک process مجبور به خاموش شدن شود (مثلاً به دلیل خرابی یا نیاز به بروزرسانی)، باید بتواند به صورت سالم خاموش شود. یعنی تمامی کارهای جاری را به درستی به اتمام برساند یا آنها را به process دیگری منتقل کند تا داده های ما از دست نرود.
- مدیریت قطع ناگهانی: فرآیندها باید در برابر خاموشی ناگهانی یا خرابی سختافزاری نیز مقاوم باشند. برای مثال، استفاده از سیستمهای صف که در صورت قطع ارتباط، کارها را به صف بازمیگرداند، از اهمیت ویژهای برخوردار است. فرض کنید در یک سیستم پردازش داده، که یک فرآیند worker در حال پردازش یک صف از دادهها است. اگر این فرآیند به طور ناگهانی متوقف شود، کار فعلی باید به صف بازگردانده شود تا توسط یک worker دیگر مجدداً پردازش شود. این کار میتواند با استفاده از ابزارهایی مثل RabbitMQ یا بزاراهای مشابه انجام شود.
سیگنالهای خاموشی
سیگنالهای خاموشی (Shutdown Signals) در Linux به سرویس ها این امکان را میدهند تا به صورت سالم و منظم خاموش شوند. این سیگنالها کمک می کنند که برنامه ها قبل از متوقف شدن، وظایف خود را به پایان برسانند، منابع خود را آزاد کنند و فایلها را ذخیره کنند. به همین دلیل، در برنامههایی که نیاز به مدیریت دقیق دارند، مانند سیستمهای پردازش داده یا سرورها، مدیریت صحیح سیگنالهای خاموشی بسیار مهم است.
انواع سیگنالهای خاموشی
- سیگنال SIGINT (Signal Interrupt):این سیگنال وقتی ارسال میشود که کاربر کلیدهای Ctrl + C را در ترمینال فشار دهد. این سیگنال به برنامه اطلاع میدهد که باید متوقف شود. اکثر برنامهها این سیگنال را به عنوان درخواست خاموشی سالم (graceful shutdown) در نظر میگیرند.
- سیگنال SIGTERM (Signal Terminate): این سیگنال معمولاً توسط ابزارها و دستورات مدیریت process (مانند دستور kill در لینوکس) برای خاتمه دادن، به برنامه ارسال میشود. SIGTERM درخواست خاموشی سالم دارد و برنامه میتواند این سیگنال را برای اتمام فرآیندهای خود مدیریت کند.
- سیگنال SIGKILL (Signal Kill): این سیگنال فوراً برنامه را متوقف میکند و هیچ فرصتی برای خاموشی سالم به برنامه نمیدهد.SIGKILL قابل دستکاری یا مسدود کردن توسط برنامه نیست و برای متوقف کردن برنامههایی که هیچ پاسخی نمی دهند استفاده میشود.
- سیگنال SIGHUP (Signal Hang Up): این سیگنال معمولاً به برنامهها بعد از قطع ارتباط ترمینال یا کنسول ارسال میشود. برخی از برنامهها (مانند سرورها) از این سیگنال برای بارگذاری مجدد پیکربندی های خود استفاده میکنند.
- سیگنال SIGQUIT (Signal Quit): مشابه SIGINT است، اما این سیگنال باعث خاتمه برنامه به همراه تولید یک فایل (core dump) برای دیباگینگ میشود. این سیگنال معمولاً توسط Ctrl + \ در ترمینال ارسال میشود.
اصل Disposability تضمین میکند که فرآیندهای یک سیستم بتوانند به سرعت و با اطمینان شروع به کار کنند، به صورت سالم خاموش شوند و در برابر خرابیهای ناگهانی مقاوم باشند. این اصل به افزایش قابلیت اطمینان و چابکی سیستم کمک میکند و به ویژه در محیطهای مقیاسپذیر و پیچیده مانند پردازش دادههای بزرگ اهمیت زیادی دارد.
۱۰- تطابق محیط توسعه و عملیاتی (Dev/prod parity):
Keep development, staging, and production as similar as possible
این اصل به مفهوم کاهش اختلاف و تفاوت بین محیطهای توسعه (Development) و عملیات (Production) اشاره دارد. تیمهای توسعه، تست و عملیات باید بتوانند با حداقل تفاوت ممکن بین این محیطها کار کنند تا ریسکهای مرتبط با انتقال کد از محیط توسعه به عملیات کاهش یابد. هدف این اصل، به حداقل رساندن تفاوتها بین این محیطها به منظور کاهش مشکلات و افزایش پایداری در فرآیند استقرار و اجرا است.
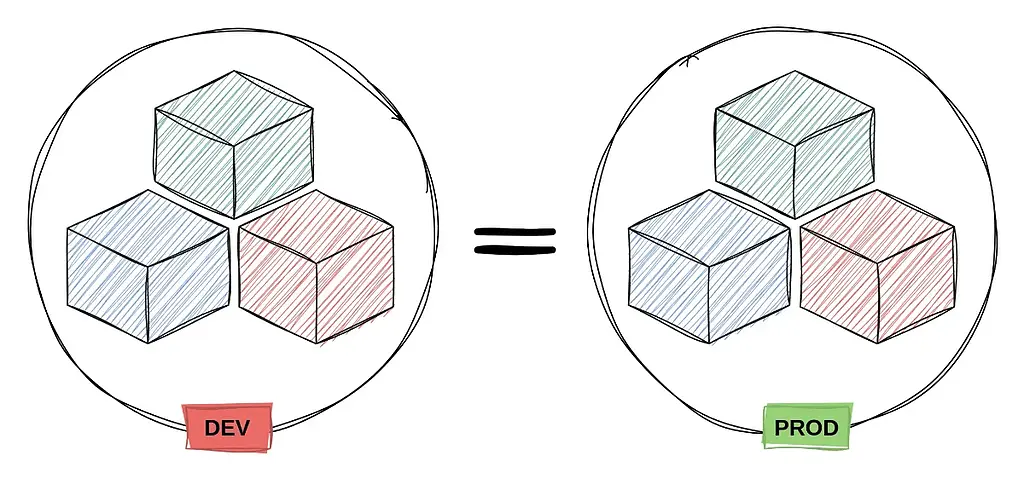
مزایای تطابق محیط های توسعه و تولید:
- کاهش فاصله زمانی بین توسعه و استقرار: در رویکردهای سنتی، بین نوشتن کد توسط توسعهدهندگان و استقرار آن در محیط تولید، ممکن است هفتهها یا حتی ماهها فاصله وجود داشته باشد. در رویکرد 12-Factor، این فاصله به ساعت یا حتی دقیقه کاهش مییابد. این امر با استفاده از CI/CD و ابزارهای خودکارسازی محقق میشود.
- افزایش مشارکت در تیم: در تیمهای سنتی، توسعهدهندگان کد را مینویسند و تیمهای عملیاتی آن را در Production مستقر میکنند. بارعایت اصول 12-Factor، توسعهدهندگان در فرآیند استقرار و نظارت بر عملکرد کد در محیط تولید نقش دارند.
- کاهش خطا در هنگام استقرار و اجرای برنامه ها: محیط Develop و Product باید تا حد ممکن مشابه باشند. استفاده از ابزارها و پیکربندیهای مشابه در هر دو محیط باعث کاهش ریسک مشکلاتی میشود که در هنگام انتقال کد به محیط production ممکن است بروز کند.
فرض کنید تیمی در حال توسعه یک پایپلاین داده است که دادهها را از یک پایگاه داده MySQL به PostgreSQL منتقل میکند. در محیط توسعه از SQLite و در محیط تولید از PostgreSQL استفاده میشود. این تفاوت در محیطها ممکن است به مشکلاتی منجر شود که در هنگام توسعه شناسایی نشدهاند. به همین دلیل، طبق اصل Dev/Prod parity، بهتر است از همان نسخه و نوع پایگاه داده در هر دو محیط استفاده شود.
برای تضمین سازگاری بین محیطهای توسعه و تولید، استفاده از کانتینرها (مثل Docker) و ابزارهای IaC (Infrastructure as Code) مثل Terraform یا Ansible نقش حیاتی دارد. Containerization تضمین میکند که پایپ لاین داده ما در هر محیطی که اجرا میشود، در یک محیط ایزوله و کنترلشده باشد. زیرساخت بهعنوان کد (IaaC) نیز امکان تعریف و استقرار محیطهای یکسان را در تمام مراحل توسعه، استیجینگ، و عملیات فراهم میکند.
services:
db:
image: postgres:latest
environment:
POSTGRES_DB: ${POSTGRES_DB}
POSTGRES_USER: ${POSTGRES_USER}
POSTGRES_PASSWORD: ${POSTGRES_PASSWORD}
POSTGRES_PORT: ${POSTGRES_PORT}
pipeline:
build: .
environment:
- DATABASE_URL=postgres://${POSTGRES_USER}:${POSTGRES_PASSWORD}@db:${POSTGRES_PORT}/${POSTGRES_DB}۱۱- لاگ ها (Logs):
Treat logs as event streams
لاگها نقش حیاتی در مانیتورینگ و اشکالزدایی برنامهها و دیتاپایپلاین ها ایفا میکنند. این اصل بر نحوهی مدیریت و برخورد با لاگها در یک اپلیکیشن تاکید دارد. به طور کلی، لاگها اطلاعاتی دربارهی وضعیت اجرای برنامه و رویدادهای رخداده در آن ارائه میدهند. این اطلاعات میتوانند شامل خطاها، درخواستها، نتایج پردازشها، و سایر فعالیتهای مهمی که در بخش های مختلف رخ می دهند باشند.
برنامههای ۱۲ عاملی لاگها را به عنوان یک جریان ساده و پیوسته از رویدادها (event stream) تولید میکنند و به مدیریت و ذخیره آنها توسط سیستمهای خارجی وابستهاند. این به معنی آن است که برنامه نباید مستقیماً به ذخیرهسازی یا مدیریت لاگها بپردازد، بلکه فقط باید لاگها را مثلاً در خروجی استاندارد تولید کند و وظیفهی تجزیه و تحلیل، ذخیره و نمایش آنها بر عهدهی سرویسهای خارجی باشد.
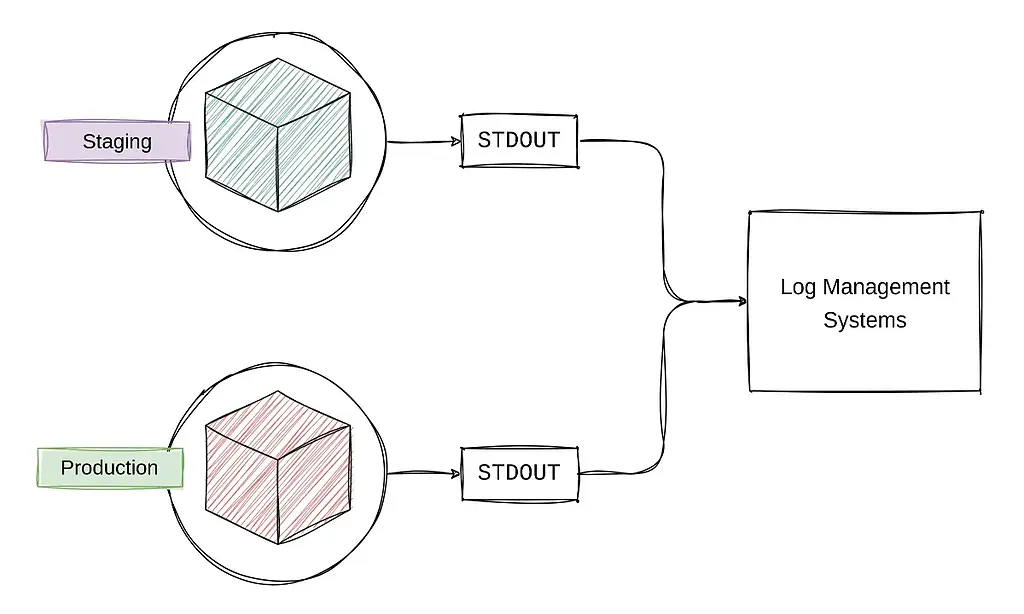
یک برنامه نباید به صورت مستقیم به مدیریت یا ذخیرهسازی لاگها بپردازد. به جای اینکه لاگها را در فایلهای محلی ذخیره کند، هر پروسهای باید خروجی خود را مستقیماً به خروجی استاندارد (stdout) ارسال کند. این جریان لاگ در محیطهای توسعه توسط توسعهدهنده در ترمینال مشاهده میشود و در محیطهای عملیاتی (مانند staging یا production)، به سیستمهای مدیریت لاگ و یا ابزارهای مانیتورینگ، ارسال میشوند.
فرض کنید شما یک سرویس پردازش داده دارید که بهطور مرتب دادههایی را از یک منبع (Source) دریافت کرده و پس از پردازش به مقصد (Destination) ارسال میکند. در هر مرحله از این پردازش، رویدادهایی مانند «دریافت داده»، «شروع پردازش»، «پایان پردازش» و «ارسال موفق به مقصد» رخ میدهند. برنامه شما باید این رویدادها را به عنوان لاگ تولید کند و به خروجی استاندارد ارسال کند.
import logging
# Log file name
log_file = 'pipeline.log'
# Create a logger
logger = logging.getLogger('data_pipeline_logger')
logger.setLevel(logging.INFO)
# Create a FileHandler to write logs to a file
file_handler = logging.FileHandler(log_file)
file_handler.setLevel(logging.INFO)
# Define the log format
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
file_handler.setFormatter(formatter)
# Add the handler to the logger
logger.addHandler(file_handler)
# Example function to generate logs
def process_data(data):
logger.info("Start processing data")
# Data processing logic here
logger.info("Data processed successfully")
if __name__ == "__main__":
logger.info("Service started")
process_data("example data")
logger.info("Service finished")بصورت خلاصه:
- اپلیکیشن نباید نگران نحوهی ذخیرهسازی و پردازش لاگها باشد.
- تمامی رخدادها باید به خروجی استاندارد ارسال شوند.
- در محیطهای staging و production، لاگها جمعآوری و به مقاصد نهایی ارسال میشوند.
- لاگها میتوانند برای تحلیل و مانیتورینگ پیشرفتهتر به سیستمهایی مدیریت لاگ مانند Splunk ارسال شوند.
با این رویکرد، دیتاپایپلاین ها میتوانند همواره از اطلاعات لاگهای خود برای بررسی و بهبود عملکرد خود استفاده کنند بدون اینکه نیاز به دخالت مستقیم در مدیریت آنها داشته باشند.
۱۲- فرایندهای مدیریتی (Admin Processes):
Run admin/management tasks as one-off processes
گاهی اوقات در راستای مدیریت دیتاپایپلاین ها عملیات مدیریتی برای نگهداری (maintenance) انجام می دهیم. این فرایندها باید بصورت یکباره و در محیط اجرایی یا عملیاتی انجام شوند. فرآیندهای مدیریتی (Admin Processes) وظایفی هستند که به طور مستقیم با عملکرد روزمره اپلیکیشن ارتباطی ندارند اما برای مدیریت و نگهداری سیستم ضروری هستند. عملیاتی مانند:
- به روزرسانی ساختار جداول و دادهها
- وارد کردن دادههای اولیه یا تستی به پایگاه داده
- پاکسازی دادهها و حذف دادههای قدیمی یا غیرفعال از سیستم
- انجام تسک های یکباره مانند اصلاح دادهها یا اجرای دستورات خاص
اصل Admin Processes به ما توصیه میکند که تمام کارهای مدیریتی را به صورت مستقل از اپلیکیشن اصلی و در همان محیط اجرا کنیم. این به معنای آن است که این فرآیندها باید:
- مستقل باشند: فرآیندهای مدیریتی نباید به عملکرد روزمره اپلیکیشن وابسته باشند و باید بتوانند به صورت جداگانه اجرا و متوقف شوند.
- از محیط اپلیکیشن استفاده کنند: برای جلوگیری از مشکلات ناشی از تفاوت محیطها، فرآیندهای مدیریتی باید در همان محیط و با همان تنظیمات و وابستگیهای اپلیکیشن اصلی اجرا شوند.
- یکپارچه باشند: تمامی فرآیندهای مدیریتی باید به صورت متمرکز و با استفاده از ابزارهای مشابه انجام شوند. ابزارهایی که برای اجرای فرآیندهای مدیریتی استفاده میشوند، باید همان ابزارهایی باشند که برای اجرای فرآیندهای اصلی برنامه نیز به کار میروند.
فرض کنید که در حال طراحی یک دیتاپایپلاین برای پردازش بیگ دیتا هستیم و نیاز به اجرای یک فرآیند مدیریتی برای بارگذاری دادههای اولیه به دیتابیس داریم. برای این منظور، باید از یک اسکریپت استفاده کنیم که دادههای ضروری را وارد پایگاه داده کند، این اسکریپت باید فقط یکبار و در محیط عملیاتی (Production) اجرا شود. در اینجا، اصل یکپارچگی فرآیندهای مدیریتی به این شکل اعمال میشود:
استفاده از ابزارهای مشابه: اگر برای اجرای برنامه از Python و Virtualenv استفاده میکنید، باید مطمئن شوید که اسکریپت بارگذاری دادهها نیز با استفاده از همین ابزارها اجرا میشود.
به عنوان مثال برای انجام این کار یک اسکریپت پایتون می نویسیم که دادههای اولیه را به پایگاه داده اضافه میکند.
import pandas as pd
from sqlalchemy import create_engine
# Database connection
engine = create_engine('postgresql://user:password@db:5432/mydb')
# Load data from a CSV file
df = pd.read_csv('data/initial_data.csv')
df.to_sql('my_table', engine, if_exists='append', index=False)در محیط عملیاتی، اسکریپت را اجرا میکنیم:
source venv/bin/activate # Activate the virtual environment python cleanup_old_data.py # Run the cleanup script
با این استفاده از این روش، فرآیند بارگذاری دادهها در محیط عملیاتی و با استفاده از همان کد و پیکربندی اجرا میشود و تضمین میکند که دادهها به درستی و بدون مشکلات هماهنگسازی به پایگاه داده اضافه شوند و فرآیند مدیریتی به طور مؤثری اجرا شود.
نیازمندی های جدید، اصول جدید:
در سال ۲۰۱۶ کتابی با عنوان "Beyond the Twelve-Factor App" منتشر شد که نویسنده در این کتاب اصول ۱۲ گانه که توسط Heroku ارایه شده بود را مورد بازبینی قرار داد و اصول جدیدی را معرفی کرد که به ۱۲ اصل اولیه اضافه شده است. این اصول به منظور پاسخگویی به نیازهای مدرن توسعه اپلیکیشنهای ابری معرفی شدهاند و شامل موارد زیر میشوند:
- تمرکز بر API: تمرکز بر طراحی و توسعه API به عنوان اولین اولویت.
- مانیتورینگ (Telemetry): مانیتورینگ و جمعآوری دادههای کاربردی برای بهبود عملکرد و امنیت.
- اهراز هویت و مجوزها (Authentication and Authorization): تمرکز بر امنیت از طریق تأیید هویت و مجوزدهی.

همچنین نویسنده در این کتاب برخی از اصول ۱۲ گانه اصلی را مورد بازبینی قرار می دهد. به عنوان مثال در این کتاب در مورد فرایندهای مدیریتی (Admin Processes) به این مورد اشاره می کند که که این رویکرد (در اصول اولیه) در شرایط خاص میتواند مشکلساز باشد و توسعهدهندگان باید به دقت بررسی کنند که آیا این نوع فرآیندها واقعاً بهترین راهحل هستند یا خیر.
نویسنده معتقد است که استفاده از فرآیندهای مدیریتی در برخی موارد میتواند مشکلاتی ایجاد کند. و به جای استفاده از روش های مدیریت سنتی، پیشنهاد میکند که از روشهای جدیدتر و مناسبتری استفاده شود. به عنوان مثال، میتوان از یک Restful end-point برای اجرای وظایف one-off استفاده کرد یا کد مرتبط با عملیات مدیریتی را از اپلیکیشن اصلی جدا کرده و به یک میکروسرویس مستقل منتقل کرد. این روشها به اپلیکیشن اجازه میدهند تا از مزایای فضای ابری بهرهمند شود و در عین حال از مشکلات احتمالی جلوگیری کنند.
این اصول جدید به منظور بهبود انعطافپذیری، امنیت، و مقیاسپذیری اپلیکیشنها در فضای ابری معرفی شدهاند و به توسعهدهندگان کمک میکنند تا اپلیکیشنهای خود را برای محیطهای ابری مدرن بهینهسازی کنند.
سخن پایانی
در این مقاله اصول ۱۲ گانه ای معرفی شد که با بکارگیری آن بتوان برنامه و دیتاپایپ لاین هایی مقیاس پذیر ساخت. Twelve Factors App یک مجموعه از اصول راهنما برای طراحی و ساخت برنامههای مدرن و مقیاسپذیر است که در محیطهای ابری اجرا میشوند. این اصول که ابتدا توسط توسعهدهندگان Heroku تعریف شدند، به گونهای طراحی شدهاند که توسعهدهندگان بتوانند برنامههایی را ایجاد کنند که به راحتی قابل نگهداری، مقیاسپذیر و پیادهسازی باشند. این اصول شامل مواردی همچون مدیریت پیکربندی، وابستگیها، جداسازی محیطها، مدیریت لاگها و غیره میباشند.
در طراحی و پیادهسازی دیتا پایپلاینها، استفاده از این اصول میتواند به بهبود مقیاسپذیری، قابلیت اطمینان، و نگهداری کمک کند. به عنوان مثال:
- کد بیس: اطمینان از اینکه کل پایپلاین یک مبنای کد واحد دارد که از طریق کنترل نسخه مدیریت میشود.
- وابستگیها: مشخص کردن دقیق وابستگیهای نرمافزاری پایپلاین به طوری که در هر محیطی قابل تکرار باشد.
- کانفیگ: جداسازی کانفیگ از کد و استفاده از متغیرهای محیطی برای کنترل تنظیمات حساس مانند کانکشن های دیتابیس.
- مدیریت فرایندها: اجرای فرآیندهای پایپلاین به صورت جداگانه و مقیاسپذیر با استفاده از کانتینرها و ابزارهای مدیریت فرآیند.
- استفاده از Port Binding: اطمینان از اینکه هر فرآیند یا سرویس در پایپلاین به صورت مستقل اجرا میشود و به پورت خاص خود متصل است.
- مقیاسپذیری: طراحی پایپلاین به گونهای که فرآیندها به صورت افقی مقیاسپذیر باشند و بتوان منابع را بر اساس نیاز به آنها اختصاص داد.
با پیادهسازی این اصول در طراحی دیتاپایپلاین، میتوان اطمینان حاصل کرد که این سیستمها به شکلی ساخته شدهاند که مقیاسپذیر، قابل نگهداری، و انعطافپذیر برای تغییرات و توسعههای آینده باشند. این اصول باعث میشوند که پایپلاینها به راحتی در محیطهای مختلف قابل پیادهسازی بوده و به سرعت به تغییرات نیازمندیها پاسخ دهند.
منابع :
https://12factor.net/
اگر این مطلب برای شما مفید بود آن را با دوستان خود به اشتراک بگذارید. نظرات ارزشمند و حمایت شما به بهبود مطالبی که در آینده ارایه می شود کمک می کند.

دیدگاه خود را بنویسید